This module is currently in beta release. The module and/or documentation may be incomplete.
A Differential Expression workflow for RNA-Seq data based on the DESeq2 package from Bioconductor
Author: David Eby;Broad Institute
Contact:
gp-help@broadinstitute.org
Algorithm Version: DESeq2_1.10.1
Introduction
One common task in bioinformatics is the analysis of high-throughput RNA-seq data for the purpose of finding genes which are differentially expressed across groups of samples or phenotypes. This can be accomplished by quantification and evaluation of the read count -- the number of transcripts that map to each genomic region -- which is an approximate measurement of the abundance of the target transcript [1]. Typically, read counts are mapped and attributed to genes, allowing a user to evaluate the transcription at a gene level. To determine differential expression, read counts can be compared between different classes, which are groupings of samples based on, e.g. differing phenotypes, barcodes, or transcription factor binding sites.
Algorithm
Although many methods exist for analyzing RNA-seq read counts, several challenges exist. Due to the nature of RNA sequencing, the resulting data can have small replicate numbers, a large dynamic range, or contain many outliers. Therefore, analysis of RNA-seq data must take these issues into account.
DESeq2 is a popular algorithm for analyzing RNA-seq data [2], which estimates the variance-mean depending in high-throughput count data, and determines differential expression based on a negative binomial distribution [3]. DESeq2 improves upon the previously published DESeq algorithm, by improving stability and interpretability of expression estimates.
The GenePattern DESeq2 module takes RNA-Seq raw count data as an input, in the GCT file format. These raw count values can be generated by HTSeq-Count [4], which determines un-normalized count values from aligned sequencing reads and a list of genomic features (e.g. genes or exons). The HTSeq-Count tool is not currently available on GenePattern. If you have data from HTSeq-counts, the GenePattern MergeHTSeqCountx module will merge multiple samples together into one GCT file, which can then be passed to DESeq2. Note that DESeq2 will not accept normalized RPKM or FPKM values, only raw count data.
In addition to the raw count data in GCT format, the DESeq2 module requires a class file in the CLS format, which categorizes samples based on, e.g. phenotype, treatment, cell type, etc. In addition, DESeq2 accepts a confounding class file, which re-categorizes samples according to a secondary class, allowing for two-factor analysis. DESeq2 completes differential expression analysis based on the provided class files. For more than two classes, the module offers the option of comparing either in a “one-versus-all” approach, or “all-pairs” approach.
In the following example, we have a two-factor analysis grouped by two sets of classes: (1) cell type (acute myeloid leukemia vs. multiple myeloma); and (2) treatment type (drug-treated vs. untreated). Since there are two variants in each class, this gives us a total of four classes.
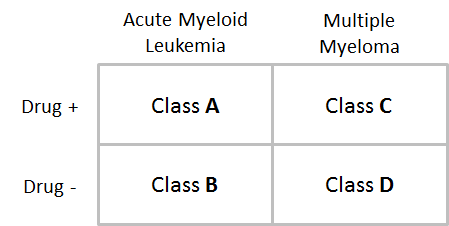
If we wanted to complete a single-factor analysis, e.g. just by treatment type, we would provide only one CLS file, and would not need to specify whether we want a “one-versus-all” or “all-pairs” analysis, since there are only two classes (drug-treated vs. untreated). However, since we have elected a two-factor approach, we provide a primary CLS file (cell type) and a confounding CLS file (treatment type), and must choose a type of analysis, resulting in the following comparisons:
-
one-versus-all: “A vs. (B and C and D)”, “B vs. (A and C and D)”, “C vs. (A and B and D)”, and “D vs. (A and B and C)”
-
all-pairs: “A vs. B”, “A vs. C”, “A vs. D”, “B vs. C”, “B vs. D”, “C vs. D”
References
- Love MI, Huber W and Anders S (2014). “Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2.” Genome Biology, 15, pp. 550. doi: 10.1186/s13059-014-0550-8.
- "DESeq2" Bioconductor, Bioconductor version: Release (3.4), https://bioconductor.org/packages/release/bioc/html/DESeq2.html, Accessed 03 Nov., 2016.
- David Bridges, "Why do we use the negative binomial distribution for analysing RNAseq data?", Bridges Lab, 30 Aug. 2015, http://bridgeslab.sph.umich.edu/posts/why-do-we-use-the-negative-binomial-distribution-for-rnaseq, Accessed 03 Nov. 2016
- "Counting reads in features with htseq-count" HTSeq 0.6.1p2 documentation, http://www-huber.embl.de/users/anders/HTSeq/doc/count.html, Accessed 03 Nov. 2016
- "Wald test." Wikipedia, https://en.wikipedia.org/wiki/Wald_test, Accessed 03 Nov. 2016
- Michael Love, Simon Anders, Vladislav Kim and Wolfgang Huber. "RNA-seq workflow: gene-level exploratory analysis and differential expression" Bioconductor, http://www.bioconductor.org/help/workflows/rnaseqGene/#plotting-results. Accessed 03 Nov. 2016
Parameters
| Name | Description |
|---|---|
| input file * | A GCT file containing raw RNA-Seq counts, such as is produced by MergeHTSeqCounts |
| cls file * | A categorical CLS file specifying the phenotype classes for the samples in the GCT file. This should contain exactly two classes with the control specified first. |
| confounding variable cls file | A categorical CLS file specifying an additional confounding variable, mapped to the input file samples. Use this for a two-factor comparison. |
| output file base * | The base name of the output file(s). File extensions will be added automatically. |
| qc plot format * | Choose a file format for the QC plots (or skip them completely) |
| fdr threshold * | FDR threshold to use in filtering before creating the reports of top up-regulated and down-regulated genes |
| top N count * | Max gene count to use when creating the reports of top up-regulated and down-regulated genes |
| random seed * | Seed to use for randomization |
* - required
Input Files
- input file
The GenePattern DESeq2 module takes RNA-Seq raw count data as an input, in the GCT file format. These raw count values can be generated by HTSeq-Count, which determines un-normalized count values from aligned sequencing reads and a list of genomic features (e.g. genes or exons). The HTSeq-Count tool is not yet available on GenePattern. If you have .count data from HTSeq-count, run outside of GenePattern, the GenePattern MergeHTSeqCounts module will merge multiple samples together into one GCT file, which can then be passed to DESeq2. Note that DESeq2 will not accept normalized RPKM or FPKM values, only raw count data. - cls file
In addition to the raw count data in GCT format, the DESeq2 module requires a class file in the CLS format, which categorizes samples based on, e.g. phenotype, treatment, cell type, etc. - confounding variable cls file
In addition, DESeq2 accepts a confounding class file, which re-categorizes samples according to a secondary class, allowing for two-factor analysis.
Output Files
DESeq2 will create a several output files for each comparison:
The results of the DESeq2 analysis. The results are automatically ordered by the “padj” variable, which is the Benjamini-Hochberg adjusted p-value for multiple hypothesis testing. The results columns are as follows:
- *_results_report.TXT
- id: the feature identification value, e.g. gene name, Ensembl ID, barcode, etc.
- baseMean: intermediate mean of normalized counts for all samples. This considers all samples in the dataset and determines the average normalized count value, dividing by size factors.
- log2FoldChange: log2 fold change when comparing two classes. This estimates effect size. It says how much a gene’s expression seems to have changed due to, e.g. treatment (class 1), when compared to untreated samples (class 2).
- lfcSE: standard error estimate for the log2 fold change estimate.
- stat: Wald statistic [5]; this is the Wald test statistic result for the log2 fold change when comparing classes.
- pvalue: Wald test p-value
- padj: Benjamini-Hochberg adjusted p-value
- *_mean_values_by_class.TXT:
The per-row mean of values organized by class, with the same ordering as in the *_results_report.txt file. This file contains the feature ID and the per-row mean for each class in individual columns. - *_topN_upregulated_genes_report.TXT:
Filters the *_results_report.TXT file into the top N up-regulated features, based on the log2 fold change value after filtering padj < 0.1. The padj filtering threshold and the number of reported genes are adjustable. - *_topN_downregulated_genes_report.TXT:
Filters the *_results_report.TXT file into the top N down-regulated features, based on the log2 fold change value after filtering padj < 0.1. The padj filtering threshold and the number of reported genes are adjustable.
Optional Output Files:
- *.MAplot.png:
An MA plot of log2 fold change compared to the mean expression values for each feature. Red points indicate features for which the log2 fold change is significantly higher than 1 (up-regulated) or less than -1 (down-regulated) when comparing classes. - *DispEst.png
A Disperson Estimates plot, which shows the dispersion values for each gene plotted against the mean of normalized counts.
Note that, to improve performance and resource usage, the DESeq2 module pre-filters the dataset by removing any rows where the total read count is either 0 or 1; e.g. the feature has no expression value in any available class. Thus, the total rows in the results files may not match the number of rows in the input files.
Example Data
Input files can be found here : https://github.com/genepattern/DESeq2/tree/develop/gpunit/Input
Example output can be found here: https://github.com/genepattern/DESeq2/tree/develop/gpunit/Output
Note that the output was created by running with the example data, and all defaults, except that the module was configured to output pdf plots.
Requirements
This module requires R version 3.2.5 to be installed and for the server to be able to resolve the substitution value <R3.2_Rscript>, found on the command line.
Please see our Adminstrators guide for more information, or feel free to contact us directly.
Platform Dependencies
Task Type:
Gene List Selection
CPU Type:
any
Operating System:
any
Language:
R3.2.5
Version Comments
| Version | Release Date | Description |
|---|---|---|
| .02 | 2016-11-03 | Initial Beta Release |